Digital Twin of Human Lungs: Towards Real-Time Simulation and Registration of Soft Organs
Pôle Mécanique - Internal seminar
March 28, 2025
Idiopathic Pulmonary Fibrosis
The role of mechanics
- No identified bio-markers yet
- A vicious circle has been hypothesised (F. Liu et al., 2010)
- Fibrotic tissues are stiffer
- Causing higher stresses
- Causing scarring
- Leading to the progress of the disease
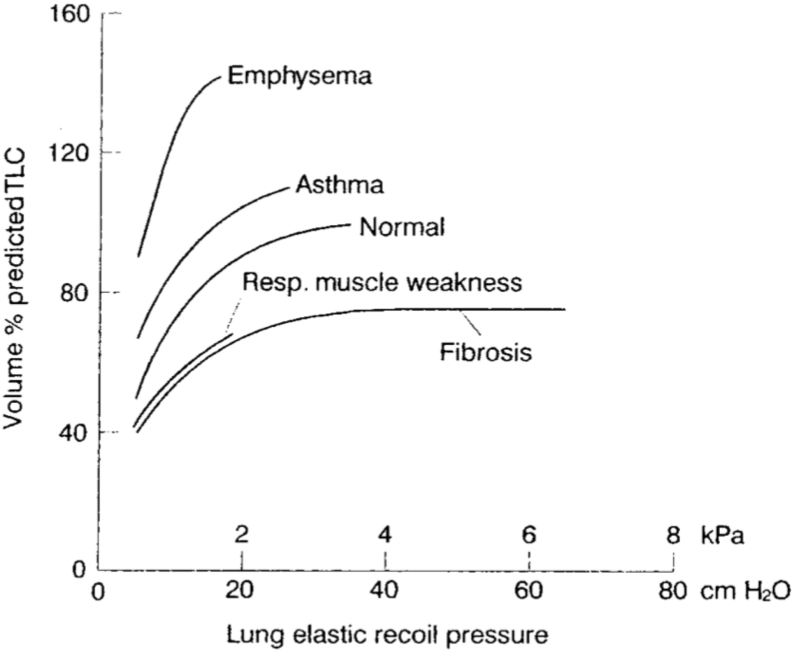
Clinician’s perspective
Rely on mechanical analysis to better understand the disease and its progression
Interpolation of the solution
- FEM finite admissible space
\[ \mathcal{U}_h = \left\{\boldsymbol{u}_h \; | \; \boldsymbol{u}_h \in \text{Span}\left( \left\{ N_i^{\Omega}\left(\boldsymbol{x} \right)\right\}_{i \in \mathopen{~[\!\![~}1,N\mathclose{~]\!\!]}} \right)^d \text{, } \boldsymbol{u}_h = \boldsymbol{u}_d \text{ on }\partial \Omega_d \right\} \]
Interpretabilty Kronecker property Easy to prescribe Dirichlet boundary conditions
Mesh adaptation not directly embedded in the method
- Physics Informed Neural Networks (PINNs)
\[ \boldsymbol{u} \left(x_{0,0,0} \right) = \sum\limits_{i = 0}^C \sum\limits_{j = 0}^{N_i} \sigma \left( \sum\limits_{k = 0}^{M_{i,j}} b_{i,j}+\omega_{i,j,k}~ x_{i,j,k} \right) \]
All interpolation parameters are trainable Benefits from ML developments
Not easily interpretable Difficult to prescribe Dirichlet boundary conditions
- HiDeNN framework (Y. Liu et al., 2023; Park et al., 2023; Zhang et al., 2021)
- Best of both worlds
- Reproducing FEM interpolation with constrained sparse neural networks
- \(N_i^{\Omega}\) are SNN with constrained weights and biases
- Fully interpretable parameters
- Continuous interpolated field that can be automatically differentiated
- Runs on GPUs

Proper Generalised Decomposition (PGD)
PGD: (Chinesta et al., 2011; Ladeveze, 1985)
Tensor decomposition
- Separation of variables
- Low-rank \(m\)
- \(\textcolor{BleuLMPS}{\overline{\boldsymbol{u}}_i(\boldsymbol{x})}\) Space modes
- \(\textcolor{LGreenLMS}{\lambda_i^j(\mu^j)}\) Parameter modes
\[\textcolor{VioletLMS}{\boldsymbol{u}}\left(\textcolor{BleuLMPS}{\boldsymbol{x}}, \textcolor{LGreenLMS}{\mu}\right) = \sum\limits_{i=0}^{m}\textcolor{BleuLMPS}{\overline{u}_i\left(x\right)}\textcolor{LGreenLMS}{\lambda_i\left(\mu\right)}\]
Discretised problem

- From \(N\times N_{\mu}\) unknowns to \(m\times\left(N + N_{\mu}\right)\)
- e.g. \(10000 \times 1000 = 1e7 \gg 5\left( 10 000+ 1000 \right) = 5.5e4\)
Proper Generalised Decomposition (PGD)
PGD: (Chinesta et al., 2011; Ladeveze, 1985)
Tensor decomposition - extra-coordinates
- Separation of variables
- Low-rank \(m\)
- \(\textcolor{BleuLMPS}{\overline{\boldsymbol{u}}_i(\boldsymbol{x})}\) Space modes
- \(\textcolor{LGreenLMS}{\lambda_i^j(\mu^j)}\) Parameter modes
\[ \textcolor{VioletLMS}{\boldsymbol{u}}\left(\textcolor{BleuLMPS}{\boldsymbol{x}}, \textcolor{LGreenLMS}{\left\{\mu_i\right\}_{i \in \mathopen{~[\!\![~}1, \beta \mathclose{~]\!\!]}}}\right) = \sum\limits_{i=1}^m \textcolor{BleuLMPS}{\overline{\boldsymbol{u}}_i(\boldsymbol{x})} ~\textcolor{LGreenLMS}{\prod_{j=1}^{\beta}\lambda_i^j(\mu^j)} \]
Discretised problem

- From \(N\times\prod\limits_{j=1}^{~\beta} N_{\mu}^j\) unknowns to \(m\times\left(N + \sum\limits_{j=1}^{\beta} N_{\mu}^j\right)\)
- e.g. \(10000 \times 1000^2 = 1e10 \gg 5\left( 10 000+ 2\times 1000 \right) = 6e4\)
- Finding the tensor decomposition by minimising the energy \[ \left(\left\{\overline{\boldsymbol{u}}_i \right\}_{i\in \mathopen{~[\!\![~}1,m\mathclose{~]\!\!]}},\left\{\lambda_i^j \right\}_{ \begin{cases} i\in \mathopen{~[\!\![~}1,m\mathclose{~]\!\!]}\\ j\in \mathopen{~[\!\![~}1,\beta \mathclose{~]\!\!]} \end{cases} } \right) = \mathop{\mathrm{arg\,min}}_{ \begin{cases} \left(\overline{\boldsymbol{u}}_1, \left\{\overline{\boldsymbol{u}}_i \right\} \right) & \in \mathcal{U}\times \mathcal{U}_0 \\ \left\{\left\{\lambda_i^j \right\}\right\} & \in \left( \bigtimes_{j=1}^{~\beta} \mathcal{L}_2\left(\mathcal{B}_j\right) \right)^{m-1} \end{cases}} ~\underbrace{\int_{\mathcal{B}}\left[E_p\left(\boldsymbol{u}\left(\boldsymbol{x},\left\{\mu_i\right\}_{i \in \mathopen{~[\!\![~}1, \beta \mathclose{~]\!\!]}}\right), \mathbb{C}, \boldsymbol{F}, \boldsymbol{f} \right) \right]\mathrm{d}\beta}_{\mathcal{L}} \label{eq:min_problem} \]
Neural Network PGD
Graphical implementation of Neural Network PGD
\[ \boldsymbol{u}\left(\textcolor{BleuLMPS}{\boldsymbol{x}}, \textcolor{LGreenLMS}{\left\{\mu_i\right\}_{i \in \mathopen{~[\!\![~}1, \beta \mathclose{~]\!\!]}}}\right) = \sum\limits_{i=1}^m \textcolor{BleuLMPS}{\overline{\boldsymbol{u}}_i(\boldsymbol{x})} ~\textcolor{LGreenLMS}{\prod_{j=1}^{\beta}\lambda_i^j(\mu^j)} \]
Interpretable NN-PGD
- No black box
- Fully interpretable implementation
- Great transfer learning capabilities
- Straightforward implementation
- Benefiting from current ML developments
- Straightforward definition of the physical loss using auto-differentiation

Hybridising ROM with NN



Stiffness and external forces parametrisation
Illustration of the surrogate model in use (preprint: Daby-Seesaram et al., 2024)

Parameters
- Parametrised stiffness \(E\)
- Parametrised external force \(\boldsymbol{f} = \begin{bmatrix} ~ \rho g \sin\left( \theta \right) \\ -\rho g \cos\left( \theta \right) \cos\left( \phi \right) \\ \rho g \cos\left( \theta \right) \sin\left( \phi \right) \end{bmatrix}\)
NN-PGD
- Immediate evaluation of the surrogate model
- Straightforward differentiation capabilities regarding the input parameters
Accuracy with regards to FEM solutions
| Solution | Error |
|---|---|
 \(E = 3.8 \times 10^{-3}\mathrm{ MPa}, \theta = 241^\circ\) |
 \(E = 3.8 \times 10^{-3}\mathrm{ MPa}, \theta = 241^\circ\) |
 \(E = 3.1 \times 10^{-3}\mathrm{ MPa}, \theta = 0^\circ\) |
 \(E = 3.1 \times 10^{-3}\mathrm{ MPa}, \theta = 0^\circ\) |
| \(E\) (kPa) | \(\theta\) (rad) | Relative error |
|---|---|---|
| 3.80 | 1.57 | \(1.12 \times 10^{-3}\) |
| 3.80 | 4.21 | \(8.72 \times 10^{-4}\) |
| 3.14 | 0 | \(1.50 \times 10^{-3}\) |
| 4.09 | 3.70 | \(8.61 \times 10^{-3}\) |
| 4.09 | 3.13 | \(9.32 \times 10^{-3}\) |
| 4.62 | 0.82 | \(2.72 \times 10^{-3}\) |
| 5.01 | 2.26 | \(5.35 \times 10^{-3}\) |
| 6.75 | 5.45 | \(1.23 \times 10^{-3}\) |
Multi-level training

Strategy
- The interpretability of the NN allows
- Great transfer learning capabilities
- Start with coarse (cheap) training
- Followed by fine tuning, refining all modes
- Great transfer learning capabilities
- Extends the idea put forward by (Giacoma et al., 2015)
Note
- The structure of the Tensor decomposition is kept throughout the multi-level training
- Last mode of each level is irrelevant by construction
- It is removed before passing onto the next refinement level
III - Patient-specific parametrisation
|
|

Shape model - available data
CT scans
- Raw 3D images
- Segmented 3D images

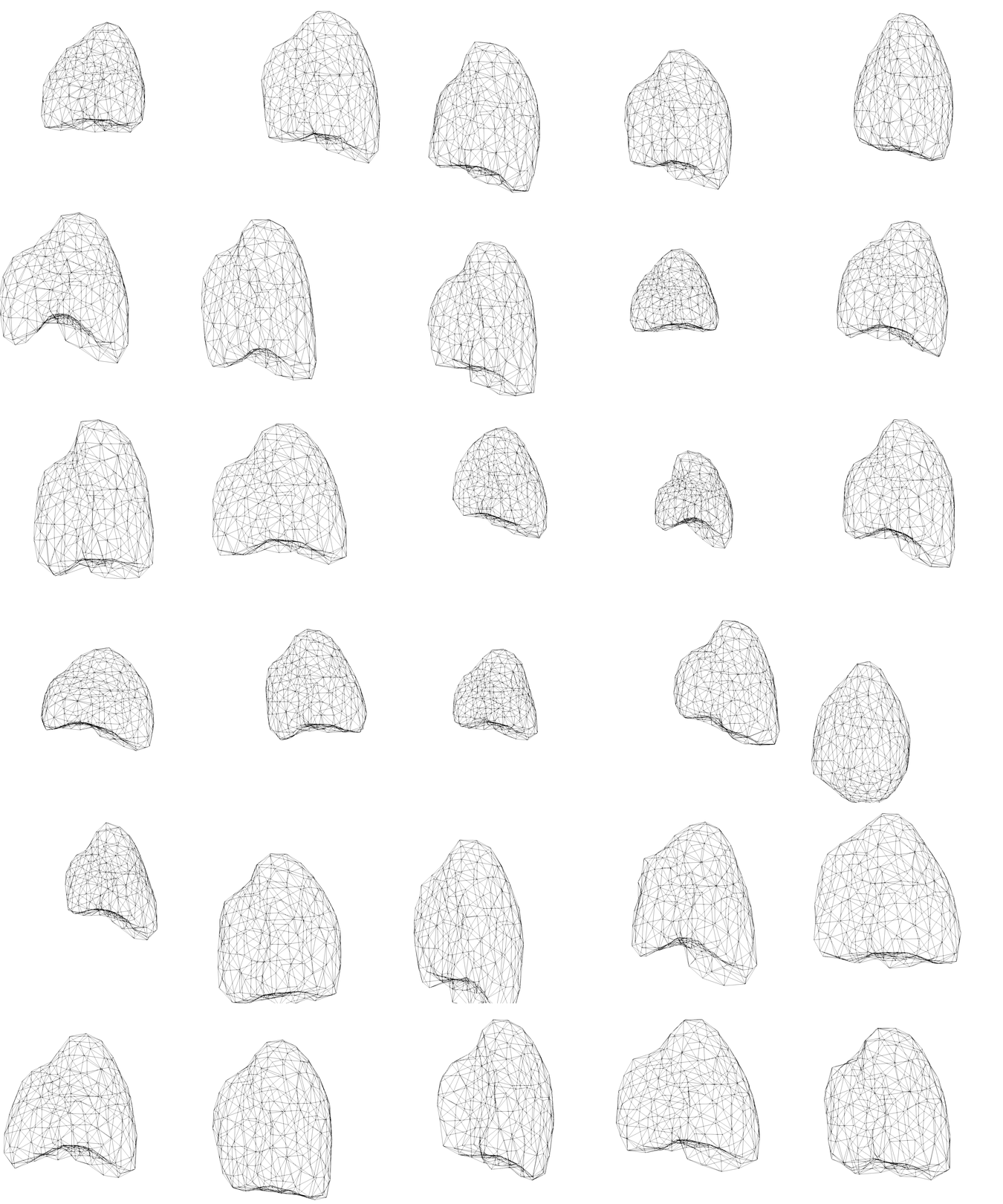
Shape model - parametrisation
Encoding the shape of the lung in low-dimensional spaces
- in order to feed the surrogate model we need a parametrisation of the lung
- ROM on the shape mappings library
Conclusion
Conclusion
- Robust and straightforward general implementation of a NN-PGD
- Interpretable
- Benefits from all recent developments in machine learning
- Surrogate modelling of parametrised PDE solution
- Promising results on simple toy case
Perspectives for patient-specific applications
- Implementation of the poro-mechanics lung model (Patte et al., 2022)
- Further work on parametrising the geometries
- Inputting geometry parameters in the NN-PGD
- Error quantification on the estimated parameters
Other perspectives
- A priori error control of the surrogate model
- Sparse/stochastic integration on the parametric hypercube
- Enhanced seamless pipeline merging all developments
Heterogeneous stiffness
- Bi-stiffness structure with unknown
- Stiffness jump \(\Delta E\)
- Jump position \(\alpha\)
- Towards the parametrisation of the disease’s progression
- Can be adapted to different stages of the diseases
- Different physiological initial stiffness


Heterogeneous stiffness
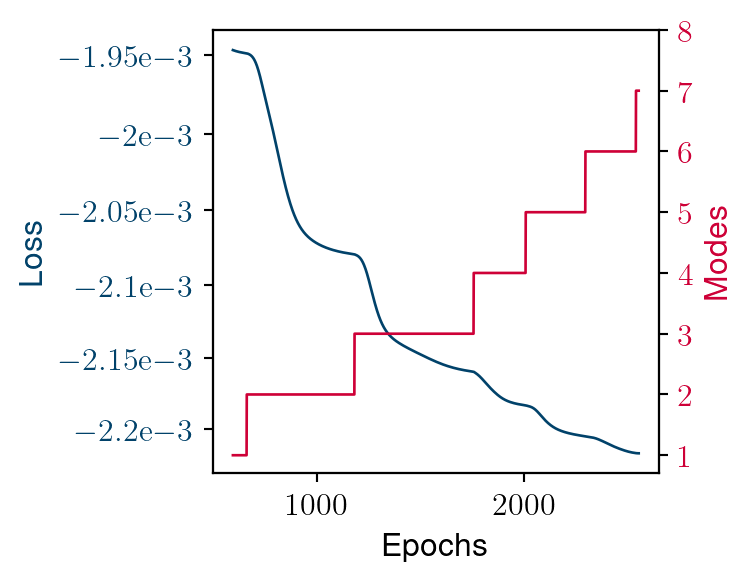
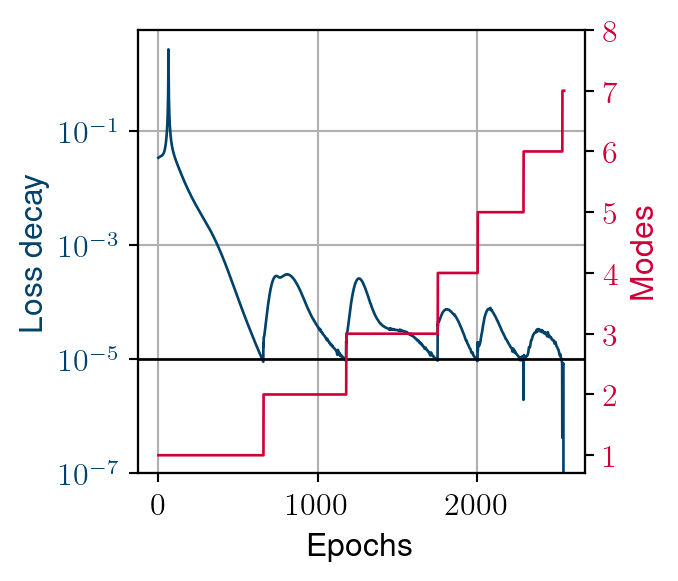
Convergence process
- Larger Kolmogorov n-with’s example
- Similar behaviour in constructing the reduced-order basis
- Adding a mode leads to a recovery in loss decay
- This recovery decreases until global stagnation
![]()